0x01 背景前言
最近分析一批恶意样本数据,考虑到数据量以及开箱即用的图表分析,所以决定把数据放在ES上,用Kibana来分析。因为是自己在用,所以只要能快速跑起来,撑的住小几T数据的秒级查询、分析即可。综合速度、便捷性等方面,工作流大致如下:写streaming_bulk,存es、分词ik_max_word、检索kibana、迁移elasticdump/logstash。这个过程没啥高深技术卷入其中,更多只是从众多功能项中,筛选出满足需求,适合单机快速运转的小方案,记上一笔,方便日后用到节省时间。
0x02 环境篇
⚠️ 由于软硬件选用、性能调优出发点是个人单机,线上环境可能并不适合。
1、环境部署
基本环境部署没什么好说的,跟着网上步骤走一遍即可,软件用的是ELK 7.10.1,主环境安装在windows上,同时为了方便调试本地也拉了个docker测试环境;硬件上4核CPU(性能高建议8核~16核)、HDD+SSD、24G内存(性能高建议64G)。推荐两个部署源:
https://github.com/deviantony/docker-elk
https://mirrors.huaweicloud.com/elasticsearch/2、性能调优
- JVM优化
根据官方给出的建议,JVM配置为机器一半的内存,不超过32G,且Xms和Xmx值尽可能保持一致。
config/jvm.options
-Xms12g
-Xmx12g- 系统优化(Linux)
# 关闭交换分区,防止内存置换降低性能。 将/etc/fstab 文件中包含swap的行注释掉
sed -i '/swap/s/^/#/' /etc/fstab
swapoff -a
# 单用户可以打开的最大文件数量,可以设置为官方推荐的65536或更大些
echo "* - nofile 655360" >> /etc/security/limits.conf
# 单用户线程数调大
echo "* - nproc 131072" >> /etc/security/limits.conf
# 单进程可以使用的最大map内存区域数量
echo "vm.max_map_count = 655360" >> /etc/sysctl.conf
# 修改立即生效
sysctl -p索引优化
- 分片副本:自己用单节点分片建议3个以内,每个分片30GB左右,1个副本,具体根据实际使用调节,目前保持 Elasticsearch7.0 的默认1个分片、1个副本。
- 数据结构:避免使用动态生成的Mapping,手动构造Mapping。
- 减少字段:对于较多不需要检索的字段,建议用MySQL等其他数据库组合的方式做联合存储。
- 写入优化
Elasticsearch近实时的本质是:最快1s写入的数据可以被查询到。 如果refresh_interval设置为1s,势必会产生大量的segment,检索性能会受到影响。 所以非实时的场景可以调大,设置为30s,甚至-1。即:在写入过程中修改刷新时间和副本数来提升写入的速度,等到写入结束后再修改回去。
GET /ASM_Assets/_settings
PUT /ASM_Assets/_settings
{
"index" : {
"refresh_interval" : "-1",
"number_of_replicas": 0
}
}同时用buk或streaming_bulk批量写的方式,目前主要用的streaming_bulk基本能够达到数据录入的时间、文档的要求。根据不同场景、侧重需求情况,可以参考py-elasticsearch的stream_bulk、parallel_bulk、bulk性能对比作者给出的测试结果选择适合的批量写入的方式。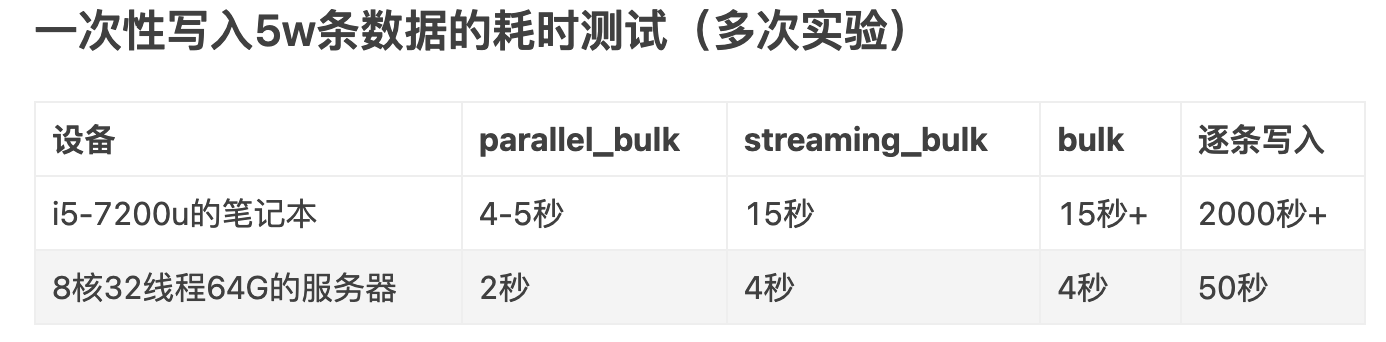
0x03 操作篇
1、常用REST API
- 创建索引
PUT index_two
{
"mappings":
{
"properties":
{
"name":
{
"type": "keyword"
}
}
},
"settings":
{
"index":
{
"number_of_shards": 1,
"number_of_replicas": 2
}
}
}- 删除索引
# 删除索引数据,保留结构
POST index_one/_delete_by_query
{
"query": {
"match_all": {
}
}
}
# 删除索引
DELETE /index_one,index_two- 查看索引
# 查看A开头索引
GET /_cat/indices/A*?v
# 查看索引状态
GET /_cat/indices/ASM_ips
# 查看索引设置
GET /ASM_ips/_settings
# 查看索引mapping
GET /ASM_ips/_mapping2、常用检索语法
- KQL
# 查询response字段中包含200的文档对象
response:200
# 模糊查询response字段中包含200的文档对象
response:*200或者response:200*
# 不区分大小精确查询某字符串
message:"hello world yes"
# 不区分大小无序查询包含其中某个字符串
message:hello world
# 关系查询
(name:jane and addr:beijing) or job:teacher
response:(200 or 404)
not response:200
response:(200 and not yes)
@timestamp < "2021"
# 查询所有包含response字段的文档对象。
response:*
# 查询搜索列machine开头,字段内容包含hello的数据记录
machine*:hello- Lucene
# 返回结果中需要有http_host字段
_exists_:http_host
# 不能含有http_host字段
_missing_:http_host
# 通配符模糊匹配
kiba?a, el*search
# 范围匹配
sip:["172.24.20.110" TO "172.24.20.140"]
date:{"now-6h" TO "now"}3、数据迁移导入/导出
- 数据批量录入(elasticsearch-py)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : Coco413
# @Summary : Batch import source data to elasticsearch
# @Usage : python3 import_es.py
try:
import simplejson as json
except ImportError:
import json
from elasticsearch import Elasticsearch, helpers
from datetime import datetime
import csv
ES = Elasticsearch(
hosts=[{"host": "127.0.0.1", "port": "9200"}],
http_auth=("xxx", "xxxx"),
retry_on_timeout=True,
max_retries=10)
def importdata_TXT(filename="ips.txt", index_name="xxx", count=0, all="N/A"):
with open(filename, "r", encoding="utf8") as fr:
for line in fr:
count += 1
pass # <根据自身需求,处理文本结构至base>
temp = {
"_op_type": 'index',
"_index": index_name,
"_source": base
}
print("[{}/{}]{}".format(count, all, temp))
yield temp
def importdata_CSV(filename="domains.csv", index_name="xxx", count=0, all="215612"):
with open(filename, "r", encoding="utf8") as fr:
for row in csv.DictReader(fr):
count+=1
pass # <根据自身需求,处理文本结构至base>
temp = {
"_op_type": 'index',
"_index": index_name,
"_source": base
}
print("[{}/{}]{}".format(count, all, temp))
yield temp
def importdata_JSON(filename="ioc.json", index_name="xxx", count=0, all="N/A"):
with open(filename, "r", encoding='utf-8') as fr:
for line in fp:
count+=1
pass # <根据自身需求,处理文本结构至base>
temp = {
"_op_type": 'index',
"_index": index_name,
"_source": base
}
print("[{}/{}]{}".format(count, all, temp))
yield temp
for ok, response in helpers.streaming_bulk(client=ES, max_retries=5, chunk_size=5000, actions=importdata_TXT()):
if not ok:
print(response)- 少量数据导出(elasticdump)
elasticdump --input=http://xxx:xxxx@127.0.0.1:9200/ASM_Assets --output=./my_index_mapping.json --type=mapping
elasticdump --input=http://xxx:xxxx@127.0.0.1:9200/ASM_Assets --output=./my_index_data.json --timeout=10 --sizeFile=1gb --type=data
elasticdump --input=http://xxx:xxxx@127.0.0.1:9200/ASM_Assets --output=$ | gzip > ./my_index_data.json.gz --timeout=10 --type=data
elasticdump --input=./my_index_data.json.gz --output=http://xxx:xxxx@127.0.0.1:9200/ASM_Assets --type=data- 大量数据导出(logstash)
input {
elasticsearch {
hosts => ["127.0.0.1:9200"]
user => "xxxx"
password => "xxx"
index => "*"
# query => '{ "query": { "query_string": { "query": "*" } } }'
docinfo => true
size => 5000
# schedule => "0 * * * *"
}
}
output {
file {
path => "./1.json"
# path => "./test-%{+YYYY-MM-dd HH:mm:ss}.txt"
}
stdout {
codec => json_lines #console输出, 可以注释stdout部分
}
}0x04 参考引用
Elastic Stack 实战手册-藏经阁-阿里云开发者社区
阿里云Elasticsearch 最佳实践 - Alibaba Cloud
Mapping | Elasticsearch Guide 7.10
1
1
1
1
1
1
厉害了@(你懂的)
1